
一个轻量级通用的数据同步方案
在不同的数据库系统之间做数据同步是大数据领域里常见的需求。一个典型的场景是,业务系统因为需要事务和随机查询,一般会使用 MySQL 这种数据库;数据仓库使用 Hive;ETL 之后的结果再放到 MySQL、AWS Redshift 等系统给 BI 和报表工具使用。
首先梳理一下需求和目标:
- 实时性:非实时,离线同步,一般为 T+1,或最细到小时粒度
- 扩展性:需要支持多种异构数据源,如 MySQL, Hive, ElasticSearch 等
- 性能要求:因为是离线系统,对性能要求无严格要求,但最好尽可能快,并有可能调优
- 复杂度:复杂度低,依赖少,易使用,易运维
- 功能要求:要满足全量同步和增量数据同步
解决方案
数据同步并不是一个特殊的问题,简化一下其实就是两个操作:读和写。与之类似的是数据库备份和恢复,很多数据库系统都自带这种工具,比如 MySQL 的 mysqldump 和 mysqlimport,MongoDB 的 mongodump 和 mongorestore 等。这些工具一般为了性能而使用特殊的编码格式,不会考虑通用性。但一个通用的数据同步系统,可以采用同样的思路来实现。
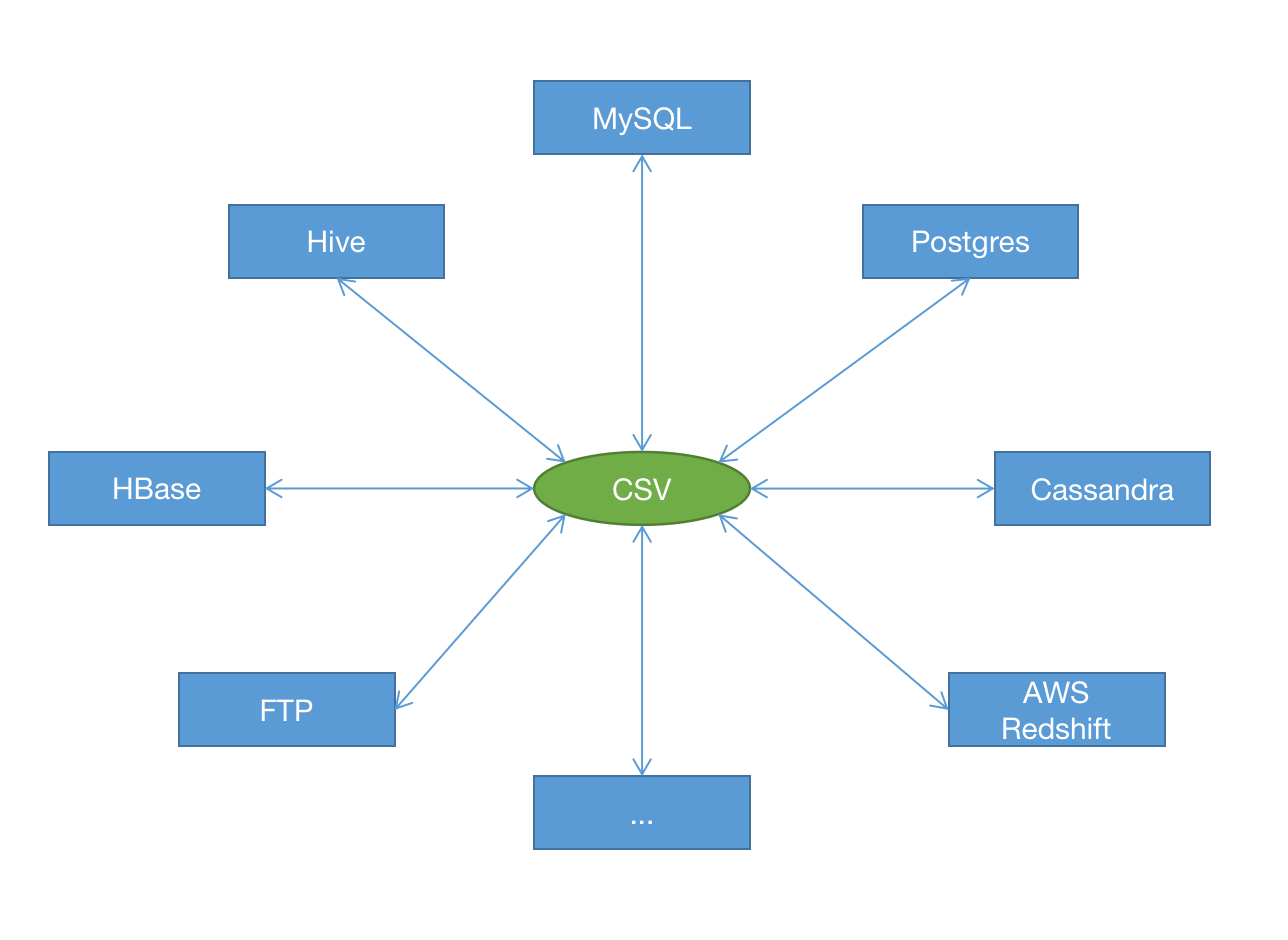
上图描述的就是本文的解决方案,即把读写拆分,通过 CSV 文件来过度。
扩展性
这种设计的核心是把数据同步抽象成导出(读)和导入(写)两个过程,完全解耦,因此具有很好的扩展性。每种数据源只需要实现读写两种操作即可。以常见的数据源为例,看看分别如何实现从 CSV 导入数据(导出到 CSV 很容易,使用任意编程语言都可实现)。
| 数据源 | 导入 CSV |
|---|---|
| MySQL | 使用 LOAD DATA LOCAL INFILE 批量加载,或读取文件运行 INSERT 语句 |
| AWS Redshift | 以 AWS S3 为中转,使用 COPY 命令批量加载 |
| Hive | 建表时指定 Serde 为 org.apache.hadoop.hive.serde2.OpenCSVSerde,或者在导入前把 CSV 先转换成默认的 TEXTFILE 格式;然后使用 LOAD DATA [LOCAL] INPATH 批量加载。 |
| ElasticSearch | 读取文件,批量插入 |
| FTP, AWS S3 | 直接上传 |
性能问题
解耦的另一个好处就是性能优化,因为我们可以专注优化导出和导入,而不用担心两者相互影响。
导出性能
导出性能优化通常是用并行化来实现,即对数据集进行分割,然后并行处理。
以 MySQL 为例,如果表里有自增主键,首先查出上下边界,分成 N 片,然后起 M 个线程来消费(Sqoop 也是这种思路,通过调整 mapper 数量来控制)。每个线程可以写单独的文件最后再合并,也可以用一个单独的线程聚合起来写入;一般来讲第一种性能更好一点。
这种优化的前提是能找到尽可能分割均匀的方式,如果有数据倾斜,可能提升并不明显,甚至退化到单线程。对数据库而言,用于分割的字段还需要有索引,一般会选择自增主键或带有索引的时间戳。并行度不能太高,否则可能对上游系统带来太大压力。另外一个实现上的细节,就是应该流式地获取数据和写入文件,而不是先全部拉到内存,否则可能导致内存占用过多,甚至 OOM.
另外,考虑到导出过程可能异常中断,还可以考虑使用 checkpoint 机制,从失败处重试。
导入性能
导入性能优化通常是用批量的思想实现。
有些数据库,如 MySQL、Hive、Redshift 等,支持直接加载 CSV 文件,这种方式一般是最高效的。如果不支持批量加载,还可以调用批量导入的 API(如 ElasticSearch 的 /_bulk,数据库的 INSERT 语句通常都支持一次性插入多条记录 )。有些数据源可能支持压缩文件(如 Redshift 支持 GZIP 等多种压缩格式),则可以在导入前先压缩以缩短传输时间和带宽消耗。
导入过程的失败重试也可以使用 checkpoint 实现「断点续传」,另外还可以考虑去重机制,比如使用 bloom filter 进行检查。
复杂度
从上文的设计图即可看出,这种方案的复杂度很低,流程清晰,容易实现。除了本地文件系统,基本上没有外部依赖。实现上需要注意日志和统计,方便跟踪进度,分析问题,定位故障。
全量和增量
从复杂度的角度来看,全量同步是最容易实现的,也更好保障数据的一致性。然而随着数据量的增加,每次全量同步需要的资源消耗和时间会越来越多。增量同步很有必要,也更复杂。
增量导出
增量导出的前提是能识别出新增数据。最容易想到的是通过自增主键来判断,但这受限于数据库本身的特性。有些数据库不支持自增主键,有些数据库的自增主键不保证单调性(如 TiDB,部署了多个 tidb-server 可能出现后插入的 ID 比之前的 ID 更小) 。更可靠的是通过时间来判断,时间天然自增且严格单调,另一个好处是对于周期性增量同步其实不用保存 checkpoint,可以直接计算得到。
有单调递增的整数或时间字段(最好是时间)是增量导出的必要条件,另外为了更好的导出性能,这个字段还需要建索引。
增量导入
增量导入要考虑更多情况,比如导入模式和幂等性。
首先看导入模式,可以分为两种:合并(MERGE)和追加(APPEND)(其实还有一种特殊的增量导入,如导入到 Hive 的一个分区,跟全量导入(OVERWRITE)是一样的)。
-
MERGE: 上游系统里新增和更新的记录,都要同步到目标系统,类比UPSERT -
APPEND: 上游系统只会新增,不会更新,类比INSERT
APPEND 的实现比较简单,但如果导入多次,(没有唯一性约束时)容易产生重复数据(不幂等)。而实际上,APPEND 是 MERGE 的一种极端情况,因此可以转换成 MERGE 来实现。
实现 MERGE 的前提是需要有字段能区分记录的唯一性,比如主键、唯一性约(只要逻辑上能区分即可)。不同数据源实现 MERGE 的方式也比较多样。有些数据源支持 UPSERT 操作,如 Phoenix, Kudu, MongoDB 等; ElasticSearch 索引文档时也类似 UPSERT ;有些数据库支持 REPLACE 操作;MySQL 还有 INSERT ON DUPLICATE UPDATE。实际上,对于 MySQL, Redshift, Hive 这些关系型数据库,还有一种通用的方案:使用 FULL JOIN 或 LEFT JOIN + UNION ALL(在 聊聊幂等 有详细阐述)。
这种实现的增量导入有个局限性,即无法同步上游系统的物理删除操作。如果有这种需求,可以考虑改成软删除,或使用全量同步。
导入流程
不管是全量还是增量,导入过程至少需要确保两点:「事务性」和不能(尽可能少)影响目标数据的使用。这个问题主要出现在数据库系统,对于 ElasticSearch 和对象存储这种场景一般不会出现。
「事务性」指的是对于要导入的数据,要么全部成功,要么全部失败,而不能出现只导入部分的情况。
导入过程中,目标数据应该是可用的,或者受影响时间要尽可能短。比如不能出现长时间锁表,导致无法查询。
可以在流程上进行优化:先导入到 staging 表,准备最终结果表,然后替换到目标表。导入 staging 表时可以不断删除重试,确保新数据完全导入后再进行下一步操作。全量导入时,可以直接把 staging 表重命名为目标表,或使用 INSERT OVERWRITE 语句进行数据拷贝。增量导入时,要再建一个中间表用于存放结果数据,完成后使用重命名或数据拷贝的方式更新到目标表。
局限性
主要有两个局限性:1. 需要落盘;2. CSV.
在某些场景下,落盘到文件可能会带来一些额外的性能损耗,不过在离线系统里,这个影响应该可以忽略。需要注意文件清理,否则可能用完整个磁盘空间。最大的问题应该是导出和导入没有完全解耦,必须部署在同一台机器,而且要确保使用相同的文件路径。因为这个状态,一定程度上限制了分布式水平扩展的能力(注意,只是单个表的同步需要在一台机器完成,多个表之间可以水平扩展)。
使用 CSV 文件作为数据交换格式,其实是一种折衷方案,优点和缺陷并存。关于 CSV 格式,我在 这篇文章 里也有讨论。这里再总结一下不足:
- 无法区分数字和和碰巧由数字组成的字符串。不过这个可以通过额外的 schema 来解决,比如导出数据的同时,也导出一份 schema,或者在导入时由目标数据库的 schema 来决定。
- 不支持二进制数据。
- 可能会有转义的问题。
- 无法区分空字符串和空值(
None,NULL),一种解决方案是使用特殊值表示空值,如\N.
整体来讲,使用 CSV 应该可以满足 90% 以上的使用场景。
使用 Kafka 作为数据交换总线,可以突破这些限制,但同时也增加了系统的复杂度。可根据实际情况进行选择。
SHOW ME THE CODE!
我在公司用 Python 实现了这种方案,目前已经支持十来种数据源(有些数据源只有读或写),暂时没有准备开源。思路比实现重要,本文讨论了整体方案和一些核心问题,基本上没什么复杂的技术,还是不难实现的。
欢迎关注我的公众号
